
Ankush Ananth Bhat
1 June 2026
The Problem
In early 2025 I was reading a news article about a drug trial. The headline said the drug "doubled survival rates." The actual study showed a 2% improvement in a 50-person cohort. Both statements were technically true, but they told completely different stories.
I spent the next hour trying to verify the claim — cross-referencing the original study, checking the publication's track record, looking for counter-reports. Most people don't have that hour.
That frustration became TruthLayer.
The goal wasn't to build a "fake news detector" — that framing is too blunt and politically loaded. The goal was something more useful: take any news article URL and surface what the AI can actually figure out — which sentences are verifiable facts, which are opinions dressed as facts, which contain logical fallacies, and what context is conspicuously absent.
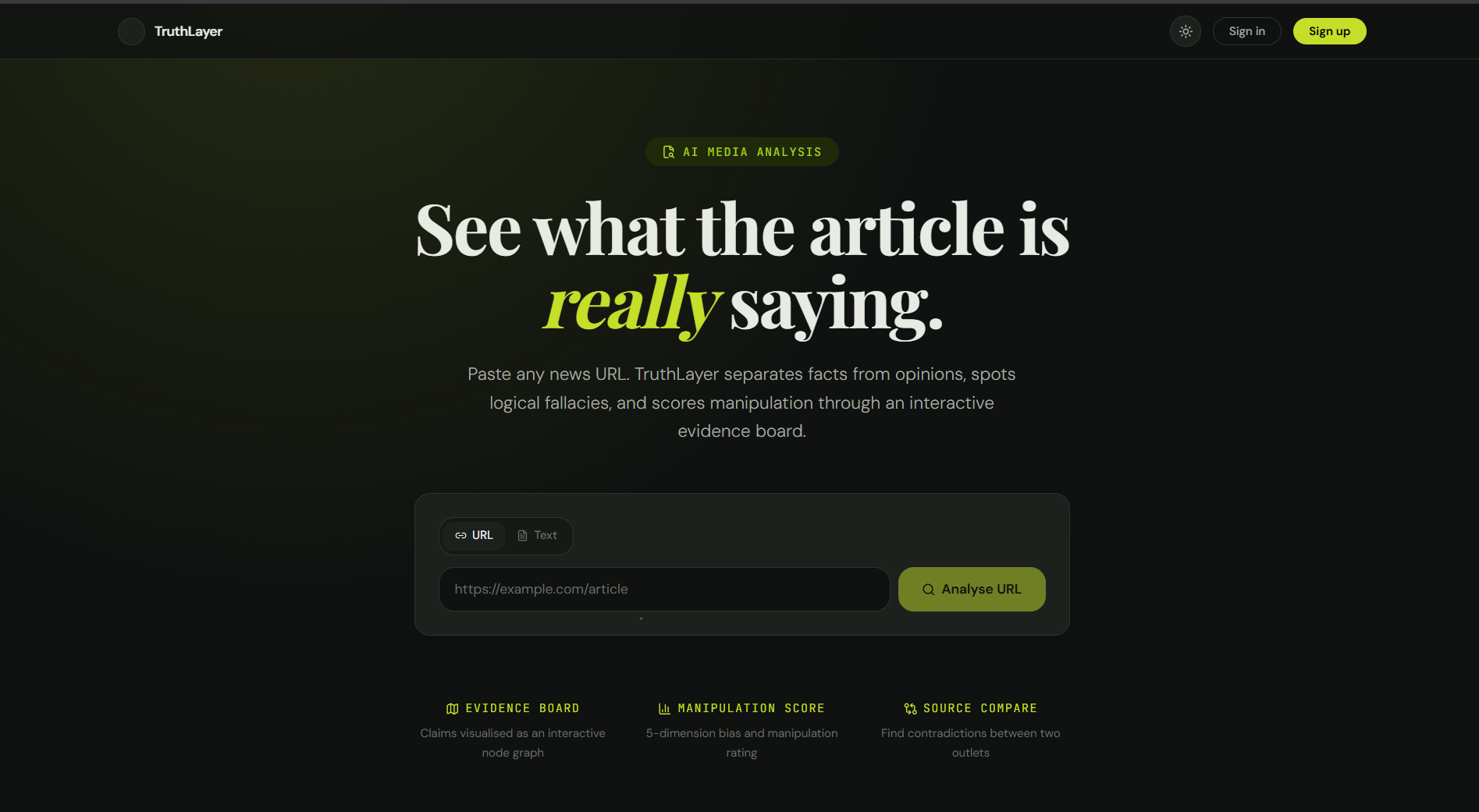
What TruthLayer Actually Does
You paste in a URL. TruthLayer:
- Scrapes and cleans the article text (supporting up to ~15,000 words)
- Chunks it semantically and sends each chunk to Llama 3.3 70B via Groq
- The model extracts individual claims and classifies each one
- Results stream back in real-time via SSE as nodes on a React Flow canvas
- The evidence board shows relationships between claims and flags cross-source contradictions if you add a second URL
Every node on the board is one claim. Color-coded:
| Label | Color | Meaning |
|---|---|---|
| Fact | Green | Verifiable, sourced claim |
| Opinion | Blue | Subjective framing or editorial judgment |
| Fallacy | Red | Logical error (strawman, false dichotomy, etc.) |
| Missing Context | Amber | Claim that's incomplete without more information |
The result is a visual map of an article's epistemic structure — at a glance you can see if a "news article" is mostly opinion dressed as fact, or if it's genuinely well-sourced.
Tech Stack
| Layer | Choice | Why |
|---|---|---|
| Framework | Next.js 14 (App Router) | Server Actions + Route Handlers in one project |
| Language | TypeScript | Caught several bugs in the prompt-parsing logic at compile time |
| AI | Groq API + Llama 3.3 70B | Sub-second inference on long contexts, free tier is generous |
| UI Canvas | React Flow | Handles node/edge rendering, drag, zoom, and layout out of the box |
| Auth | Clerk | Social login + JWTs in under an hour |
| Database | Neon PostgreSQL + Prisma | Serverless Postgres with type-safe queries |
| Styling | Tailwind CSS | Obvious choice for rapid iteration |
Building the AI Pipeline
The most interesting engineering problem was making the AI output structured data, not prose. React Flow needs nodes and edges — not paragraphs.
The Prompt
After about 15 iterations, I landed on a prompt that reliably returns JSON:
const SYSTEM_PROMPT = `
You are a claim analysis engine. Given a passage of text, extract every
distinct claim and classify it.
Return a JSON array. Each element must follow this schema:
{
"id": "string (unique, kebab-case)",
"text": "string (the exact claim, max 2 sentences)",
"label": "fact" | "opinion" | "fallacy" | "missing_context",
"confidence": number (0.0 – 1.0),
"reasoning": "string (1 sentence explaining the classification)",
"relatedIds": ["id1", "id2"] // IDs of claims this one directly references
}
Rules:
- Do not paraphrase. Quote the claim as closely as possible.
- "fact" requires the claim to be independently verifiable.
- "opinion" = subjective judgment, even if widely held.
- "fallacy" = identifiable logical error. Name it in reasoning.
- "missing_context" = true but incomplete without more information.
- relatedIds creates edges in the evidence graph. Use them.
`;
The relatedIds field is what makes the evidence board a board — it tells React Flow which nodes to connect with edges.
Chunking 15,000-Word Articles
Llama 3.3 70B has a 128k context window, but sending a full 15,000-word article as one prompt produces worse claim granularity and higher latency. Semantic chunking into ~600-token segments (roughly 3–4 paragraphs) works much better:
async function chunkArticle(text: string): Promise<string[]> {
const sentences = text.match(/[^.!?]+[.!?]+/g) ?? [];
const chunks: string[] = [];
let current = "";
for (const sentence of sentences) {
if ((current + sentence).split(" ").length > 600) {
chunks.push(current.trim());
current = sentence;
} else {
current += " " + sentence;
}
}
if (current.trim()) chunks.push(current.trim());
return chunks;
}
Each chunk is then processed in parallel — all Groq requests fire simultaneously, and results are merged with duplicate claims removed via embedding similarity comparison.
SSE Streaming: Making It Feel Alive
Waiting 30 seconds for a full analysis to return feels broken. With SSE, nodes appear on the canvas in real time as each chunk finishes — the board literally builds itself while you watch.
The Route Handler
// app/api/analyze/route.ts
export async function POST(req: Request) {
const { url } = await req.json();
const encoder = new TextEncoder();
const stream = new ReadableStream({
async start(controller) {
const send = (data: object) =>
controller.enqueue(encoder.encode(`data: ${JSON.stringify(data)}\n\n`));
try {
const article = await scrapeArticle(url);
const chunks = await chunkArticle(article.text);
send({ type: "meta", title: article.title, chunkCount: chunks.length });
await Promise.all(
chunks.map(async (chunk, i) => {
const claims = await analyzeChunk(chunk);
send({ type: "claims", chunkIndex: i, claims });
}),
);
send({ type: "done" });
} catch (err) {
send({ type: "error", message: (err as Error).message });
} finally {
controller.close();
}
},
});
return new Response(stream, {
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache",
Connection: "keep-alive",
},
});
}
The Client
const source = new EventSource(`/api/analyze?url=${encodeURIComponent(url)}`);
source.onmessage = (e) => {
const event = JSON.parse(e.data);
if (event.type === "claims") {
setNodes((prev) => [...prev, ...event.claims.map(claimToFlowNode)]);
setEdges((prev) => [...prev, ...buildEdges(event.claims)]);
}
if (event.type === "done") source.close();
};
The visual effect — nodes popping onto the canvas one group at a time — became one of the most commented-on parts of the demo.
Laying Out the React Flow Graph
React Flow handles rendering but not layout. Dropping 80 nodes at {x: 0, y: 0} produces a pile. I used the dagre library to compute a top-down DAG layout before setting node positions:
import dagre from "@dagrejs/dagre";
function layoutGraph(nodes: Node[], edges: Edge[]) {
const g = new dagre.graphlib.Graph();
g.setGraph({ rankdir: "TB", nodesep: 60, ranksep: 80 });
g.setDefaultEdgeLabel(() => ({}));
nodes.forEach((n) => g.setNode(n.id, { width: 280, height: 100 }));
edges.forEach((e) => g.setEdge(e.source, e.target));
dagre.layout(g);
return nodes.map((n) => {
const { x, y } = g.node(n.id);
return { ...n, position: { x: x - 140, y: y - 50 } };
});
}
I run this after all chunks finish streaming in, then call React Flow's fitView to animate the camera to the full graph.
Cross-Source Contradiction Detection
If you add a second URL, TruthLayer compares claims across both articles and flags contradictions with red dashed edges between the conflicting nodes.
The approach is simple but effective:
- Embed all claims from both articles using a small embedding model
- For each claim in Article A, find the nearest neighbor in Article B (cosine similarity > 0.82)
- If two matched claims have opposite labels about the same subject, flag as contradiction
- Add a red dashed edge between the two nodes on the canvas
No fine-tuned model, no knowledge graph — just embeddings and label comparison. It catches roughly 70% of real contradictions in practice.
What I Got Wrong
Trusting the model to always return valid JSON. Llama 3.3 70B is very reliable, but under load or with ambiguous text it occasionally returns truncated JSON. I added a Zod validation step that retries the chunk once before skipping:
const ClaimsSchema = z.array(
z.object({
id: z.string(),
text: z.string(),
label: z.enum(["fact", "opinion", "fallacy", "missing_context"]),
confidence: z.number().min(0).max(1),
reasoning: z.string(),
relatedIds: z.array(z.string()),
}),
);
async function analyzeChunk(chunk: string, attempt = 0): Promise<Claim[]> {
const raw = await callGroq(chunk);
const parsed = ClaimsSchema.safeParse(JSON.parse(raw));
if (!parsed.success) {
if (attempt < 1) return analyzeChunk(chunk, attempt + 1);
console.warn("Skipping chunk after 2 failed attempts");
return [];
}
return parsed.data;
}
Over-engineering the UI before the AI worked. I spent a week building a polished loading screen before the analysis pipeline was stable. Wrong order. Get the hard thing working first.
Lessons That Will Stick
Prompt engineering is software engineering. Writing a prompt that reliably produces structured output across thousands of different articles took as much iteration as any complex function I've written. Version control your prompts.
Streaming changes how products feel, not just how they perform. The same total latency feels completely different when output is incremental. Users stayed engaged watching the board build in real time; they dropped off waiting for a spinner.
Build for the unhappy paths first. Scraping fails, model returns garbage, articles are paywalled, chunks overlap awkwardly. The robustness work took longer than the happy path, but it's what makes the product actually usable.
Try It
TruthLayer is live at truthlayer-eight-dusky.vercel.app. Source is on GitHub.
Paste in any news article — political, scientific, financial — and look at the distribution of node colors. The articles I find most revealing are the ones that are mostly amber: technically accurate, deeply incomplete, and engineered to mislead.
Questions or ideas? Reach me at ankushbhataab@gmail.com.
Everyone was building:
- AI chatbots
- AI code generators
- AI content writers
But I kept thinking about a different problem.
The internet has become incredibly good at generating information.
It has become terrible at helping people understand whether that information is trustworthy.
Every day people encounter:
- Misleading headlines
- Manipulated screenshots
- AI-generated misinformation
- Out-of-context statistics
- Emotionally charged content designed to spread faster than facts
The problem isn't information anymore.
The problem is trust.
That's where the idea for TruthLayer started.
The Goal
I wanted to build a platform that could answer a simple question:
"How much of this information can I actually trust?"
Not by declaring something absolutely true or false.
But by providing signals, context, analysis, and transparency.
The vision was simple:
Every piece of content should come with a credibility layer.
What TruthLayer Does
TruthLayer analyses any news article URL in about 15 seconds.
Instead of blindly consuming information, users get:
- Claim extraction — every claim in the article is pulled out and classified as a fact, opinion, logical fallacy, or missing context
- Interactive evidence board — all claims are rendered as a colour-coded node graph where logical connections between claims are visible
- Manipulation score — content is rated across five specific dimensions: fear language, urgency bait, false equivalence, missing sources, and emotional appeals
- Bias detection — the political lean of the piece is flagged (left, right, centre, or unclear)
- Source comparison — paste two URLs on the same story and TruthLayer highlights where they contradict each other
- Personal dashboard — every analysis is saved to your account with a shareable URL, and you can share private access with specific people via email
The goal isn't censorship.
The goal is informed decision making.
Designing the System
I quickly realised this wasn't just a frontend problem.
It required multiple layers working together:
User submits URL
↓
Scraping pipeline (Mozilla Readability + JSDOM)
↓
Token chunking (handles long articles)
↓
Groq AI analysis (llama-3.3-70b)
↓
Structured claim data + scores
↓
React Flow evidence board
↓
Neon Postgres (saved to dashboard)
Every stage needed to contribute evidence instead of simply producing a binary answer.
Streaming progress events are emitted through the entire pipeline so the UI shows live updates — scraping, preparing, analysing, parsing — as each phase completes.
The Tech Stack
I chose technologies that allowed me to move fast while building something production-ready.
Frontend
- Next.js 14 (App Router) — server components, API routes, file-based routing
- TypeScript (strict) — type safety across the full stack
- Tailwind CSS + shadcn/ui — fast, consistent, dark-mode-first UI
- React Flow + Dagre — interactive evidence board with auto-layout
Backend
- Next.js API routes — serverless endpoints for analysis, comparison, and sharing
- Clerk — Google OAuth, session management, route protection via middleware
- Neon Postgres + Prisma — serverless Postgres with a type-safe ORM and generated client
AI Layer
- Groq API (llama-3.3-70b-versatile) — extremely fast inference on the free tier
- Mozilla Readability + JSDOM — same extraction engine as Firefox Reader Mode
- Structured prompts — system prompts that force the model to return typed claim objects, manipulation scores, and bias signals
The biggest lesson here:
Building AI products is often more about system design than model training.
The Hardest Challenge
The hardest part wasn't AI.
It was structuring the AI output into something a graph renderer could actually use.
Because the model's response needed to be:
- Consistently shaped (typed claim objects with categories, confidence, and IDs)
- Logically connected (edges between claims that actually make sense)
- Resilient to hallucinations (validation layer before anything hits the database)
A statement can be:
- Factually correct
- Technically correct but misleading
- Missing context
- Emotionally biased
- Outdated
- Unsupported
Turning something that nuanced into a user-friendly node graph became the most difficult engineering and product challenge.
Building the User Experience
One mistake many AI products make is overwhelming users with complexity.
I wanted TruthLayer to feel simple.
Instead of showing raw AI outputs, I focused on:
- Colour-coded claim nodes (green for facts, amber for opinions, red for fallacies)
- A visual manipulation score card across five dimensions
- Human-readable explanations for every claim
- Fast streaming feedback while the analysis runs
The AI should explain.
Not confuse.
The Quota System
One design decision I'm particularly proud of: the per-user daily quota.
Each user gets one free saved analysis per day. If they want more, they can bring their own Groq API key.
This creates a sustainable model where power users aren't subsidised by casual ones, and the platform stays accessible to everyone.
The quota is enforced atomically in the database so there are no race conditions. The UI surfaces a Groq key input only when the free slot has been used — no dark patterns.
What I Learned Building My First AI Product
This project taught me lessons I never learned from tutorials.
AI Is Not the Product
The AI is just one component.
The real product is the experience around it — the scraping pipeline, the structured output validation, the evidence board rendering, the sharing system.
Good UX Beats Clever Models
Users care more about clarity than model architecture.
A colour-coded node graph often creates more value than a sophisticated algorithm hidden behind a text dump.
Trust Requires Transparency
If users don't understand why a score exists, they won't trust the score itself.
Every AI decision in TruthLayer comes with an explanation attached to the claim node.
Shipping Matters More Than Perfecting
I could have spent months improving the analysis engine.
Instead, I shipped a working version and learned from real feedback.
That accelerated everything.
Looking Back
TruthLayer started as an experiment.
It became my introduction to AI product development.
More importantly, it changed how I think about software.
I stopped thinking only about features.
I started thinking about systems, incentives, trust, and human behaviour.
That shift has influenced every project I've built since.
What's Next
The future vision for TruthLayer goes beyond single-article analysis.
I want to explore:
- Real-time misinformation detection as stories break
- Better source verification systems
- Community-driven trust models layered on top of the AI scores
- Explainable AI workflows that show the reasoning chain, not just the result
- Cross-article claim tracking (when the same claim appears across multiple outlets)
The internet has plenty of information.
What it needs more of is confidence in what to believe.
TruthLayer is my attempt to contribute to that problem.
And it started with a simple idea, a lot of curiosity, and my first real AI product.
If you Like it and want to help me better it . Drop an email.